WAN 2.2 Image to Video ComfyUI workflow for Videcool
The WAN 2.2 Image-to-Video workflow in Videcool provides a powerful and flexible way to generate high-quality videos from static images and text prompts. Designed for speed, clarity, and creative control, this workflow is served by ComfyUI and uses the WAN 2.2 AI image-to-video model developed by Alibaba's Wangwang team and repackaged by Comfy-Org.
What can this ComfyUI workflow do?
In short: Image to video conversion.
This workflow converts static images into fully generated videos using diffusion technology. It interprets your reference image and optional text prompt, and outputs detailed, coherent video sequences with smooth motion and temporal consistency. The base AI model it uses is optimized for 576×1024 native resolution but can also produce videos in flexible aspect ratios and durations.
Example usage in Videcool
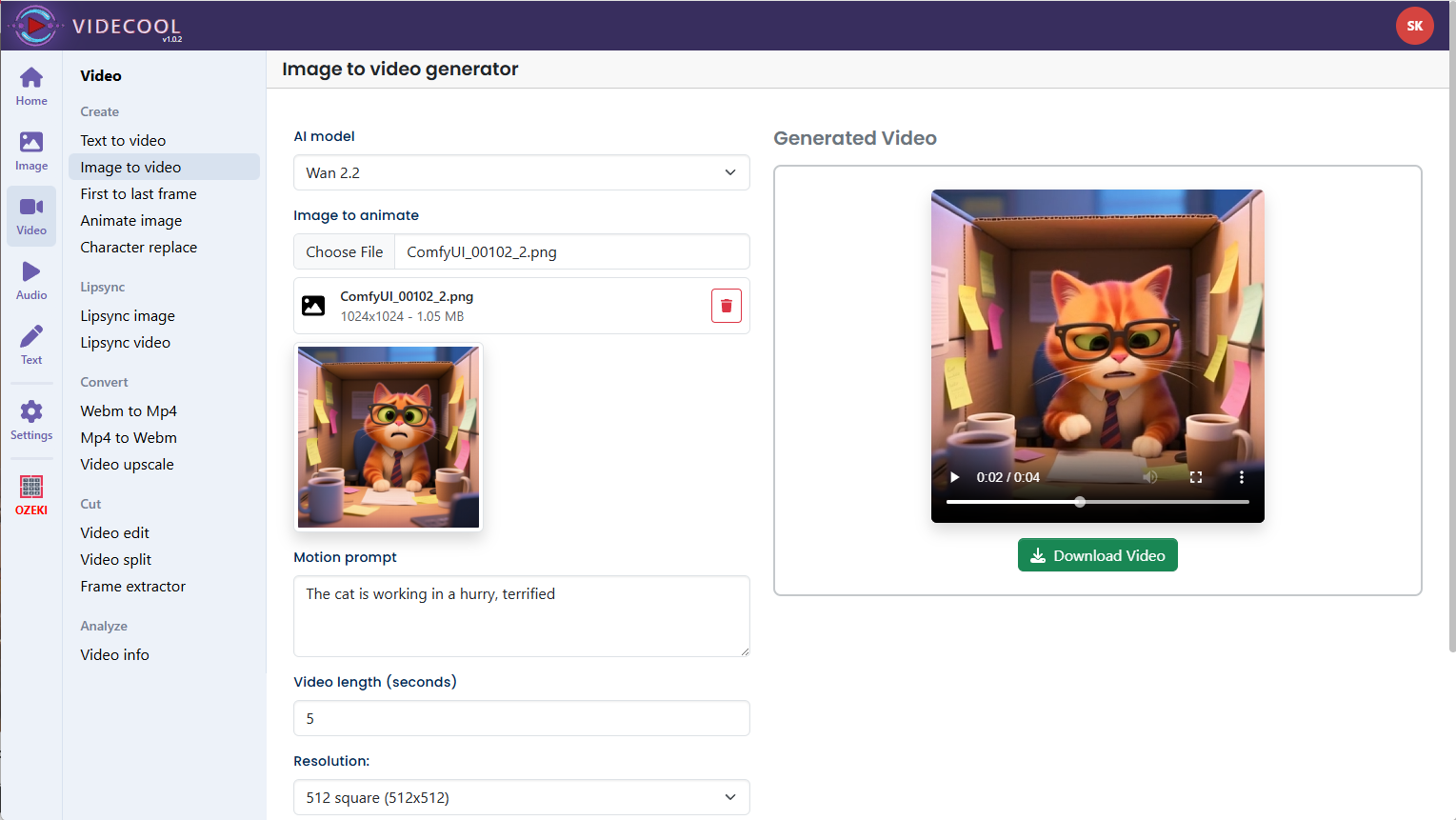
Download the ComfyUI workflow
Download ComfyUI Workflow file: Wan22I2V_API.json
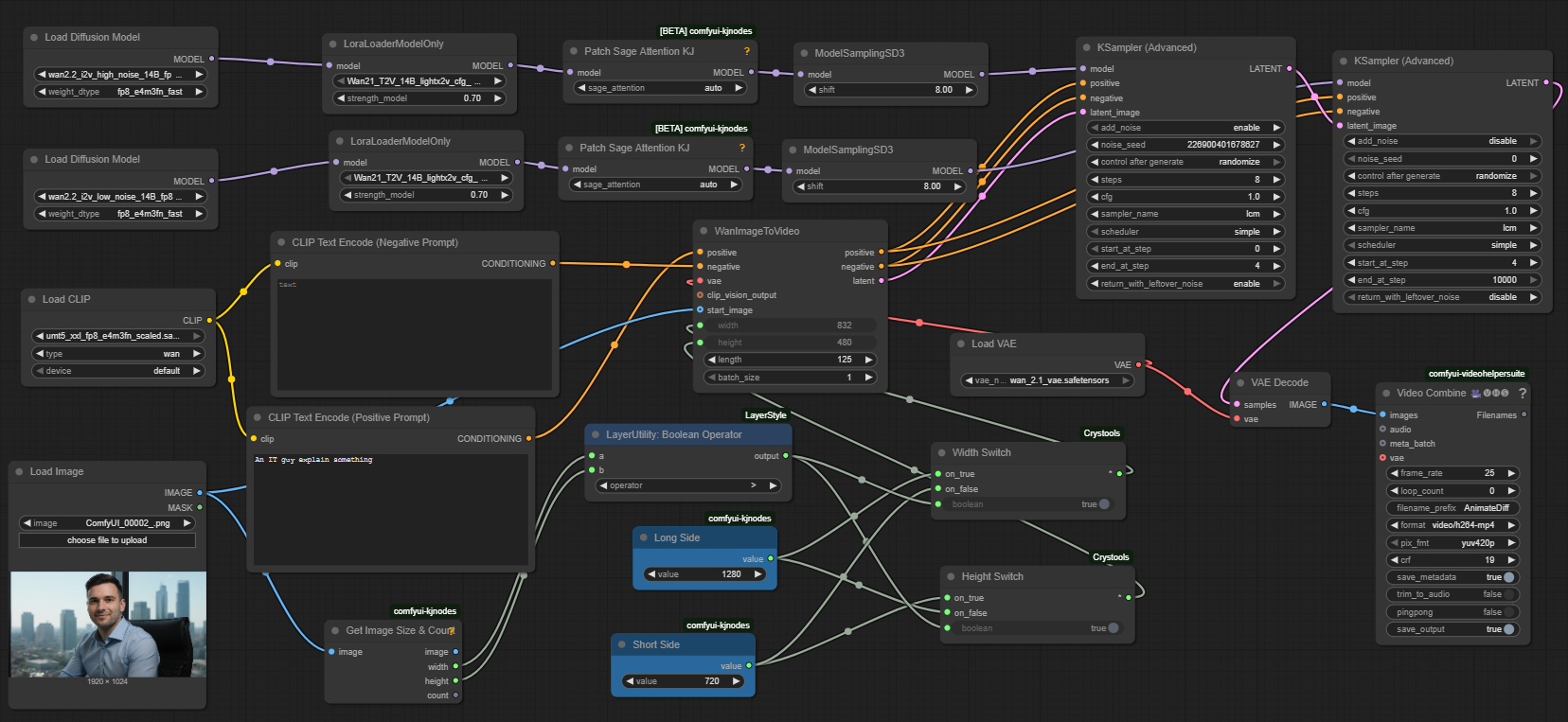
Image of the ComfyUI workflow
This figure provides a visual overview of the workflow layout inside ComfyUI. Each node is placed in logical order to establish a clean and efficient image-to-video generation pipeline. The structure makes it easy to understand how the image loader, text encoders, model loader, sampler, and VAE decoder interact. Users can modify or expand parts of the workflow to create custom variations.
Installation steps
Step 1: Install the RES4LYF custom node using ComfyUI Manager: Manage custom nodes → Search "RES4LYF" → Install.Step 2: Install the comfyui-kjnodes custom node using ComfyUI Manager: Manage custom nodes → Search "kjnodes" → Install.
Step 3: Install the ComfyUI-VideoHelperSuite custom node using ComfyUI Manager: Manage custom nodes → Search "VideoHelperSuite" → Install.
Step 4: Download umt5_xxl_fp8_e4m3fn_scaled.safetensors into /ComfyUI/models/text_encoders/umt5_xxl_fp8_e4m3fn_scaled.safetensors.
Step 5: Download wan_2.1_vae.safetensors into /ComfyUI/models/vae/wan_2.1_vae.safetensors.
Step 6: Download wan2.2_i2v_14B_fp8_scaled.safetensors into /ComfyUI/models/diffusion_models/.
Step 7: Download Wan2.2_I2V_14B_lightx2v_cfg_step_distill_lora_rank32.safetensors into /ComfyUI/models/loras/.
Step 8: Download the Wan22I2V_API.json workflow file into your home directory.
Step 9: Restart ComfyUI.
Step 10: Open the ComfyUI graphical user interface (ComfyUI GUI).
Step 11: Load the Wan22I2V_API.json in the ComfyUI GUI.
Step 12: In the Load Image node, select a reference image, and enter a text prompt into the text encoding node.
Step 13: Hit run to generate a video from the image.
Step 14: Open Videcool in your browser, select image to video, and choose WAN 2.2 to generate a video.
Installation video
The workflow requires only a reference image and optional text prompt plus a few basic parameter adjustments to begin generating videos. After loading the JSON file, users can select the input image, guidance scale, sampling steps, video length, and prompt text. Once executed, the sampler processes the latent representation and produces a final decoded video. The result can be saved and reused across other Videcool tools. Check out the following video to see the model in action:
Prerequisites
To run the workflow correctly, download the following model files and place them into your ComfyUI directory. These files ensure the model can interpret images and language, convert them into latent video embeddings, and decode the final videos. Proper installation into the following location is essential before running the workflow: {your ComfyUI director}/models.
ComfyUI\models\text_encoders\umt5_xxl_fp8_e4m3fn_scaled.safetensors
https://huggingface.co/Comfy-Org/Wan_2.1_ComfyUI_repackaged/resolve/main/split_files/text_encoders/umt5_xxl_fp8_e4m3fn_scaled.safetensors
ComfyUI\models\vae\wan_2.1_vae.safetensors
https://huggingface.co/Comfy-Org/Wan_2.2_ComfyUI_Repackaged/resolve/main/split_files/vae/wan_2.1_vae.safetensors
ComfyUI\models\diffusion_models\wan2.2_i2v_14B_fp8_scaled.safetensors
https://huggingface.co/Comfy-Org/Wan_2.2_ComfyUI_Repackaged/resolve/main/split_files/diffusion_models/wan2.2_i2v_14B_fp8_scaled.safetensors
ComfyUI\models\loras\Wan2.2_I2V_14B_lightx2v_cfg_step_distill_lora_rank32.safetensors
https://huggingface.co/Kijai/WanVideo_comfy/resolve/main/Wan2.2_I2V_14B_lightx2v_cfg_step_distill_lora_rank32.safetensors
How to use this workflow in Videcool
Videcool integrates seamlessly with ComfyUI, allowing users to load workflows directly and generate videos from images without external complexity. After importing the workflow file, simply select your image and click generate. The system handles all backend interactions with ComfyUI. This makes video generation intuitive and accessible, even for users who are not keen on learning how ComfyUI works. The following video shows how this model can be used in Videcool:
ComfyUI nodes used
This workflow uses the following nodes. Each node performs a specific role, such as loading images and models, encoding text, sampling, and finally decoding the video output. Together they create a reliable and modular pipeline that can be easily extended or customized.
- Load CLIP
- KSampler (Advanced)
- VAE Decode
- Load VAE
- ModelSamplingSD3
- WanImageToVideo
- Load Diffusion Model
- CLIP Text Encode
- Load Image
- Video Combine VHS
- LoraLoaderModelOnly
- Patch Sage Attention KJ
- LayerUtility: Boolean Operator
- Switch any [Crystools]
- INTConstant
- Get Image Size & Count
Base AI model
This workflow is built on Alibaba's WAN 2.2 image-to-video model, a modern and highly capable diffusion-based image-to-video generator. WAN 2.2 provides clarity, coherence, and creative flexibility, making it suitable for both artistic and commercial use cases. The model benefits from advanced training data and offers consistent results across a variety of video styles and motion patterns. More details, model weights, and documentation can be found on the following links:
Hugging Face repository (Comfy-Org repack):https://huggingface.co/Comfy-Org/Wan_2.2_ComfyUI_Repackaged
WAN 2.1 text encoder repository:https://huggingface.co/Comfy-Org/Wan_2.1_ComfyUI_repackaged
WAN Video ComfyUI repository:https://huggingface.co/Kijai/WanVideo_comfy
Developer Alibaba Wangwang TeamVideo resolution and quality
WAN 2.2 image-to-video models perform best when they generate videos in their native resolution, which was used for training. For this model, information about the best resolution can be found below:
Native video size: 576×1024pxThe model supports other resolutions. Best resolutions are multiples of 32px.
Frame duration: 4 seconds at 24 fps (96 frames total)
Recommended for smooth motion generation and consistent video quality with diverse input images.
Conclusion
The WAN 2.2 Image-to-Video workflow is a robust, powerful, and user-friendly solution for generating AI-driven videos from static images in Videcool. With its combination of high-quality models, a modular ComfyUI pipeline, and seamless platform integration, it enables beginners and professionals alike to produce creative and commercial-grade videos with ease. By understanding the workflow components and advantages, users can unlock the full potential of AI-assisted image-to-video generation in Videcool.