Qwen Image to Image ComfyUI workflow for Videcool
The Qwen Image to Image workflow in Videcool provides a powerful and flexible way to transform images while maintaining structural coherence and visual quality. Designed for speed, clarity, and creative control, this workflow is served by ComfyUI and uses the Qwen Image-to-Image AI model developed by Alibaba's Qwen team and repackaged by Comfy-Org.
What can this ComfyUI workflow do?
In short: Image-to-image transformation and editing.
This workflow takes a source image and an optional text prompt to transform it into a new version while preserving key visual elements or adapting them according to your instructions. It uses advanced diffusion technology to interpret both the image content and textual guidance, producing detailed and coherent outputs. The base Qwen model is optimized for maintaining image structure and quality across various editing tasks and stylistic transformations.
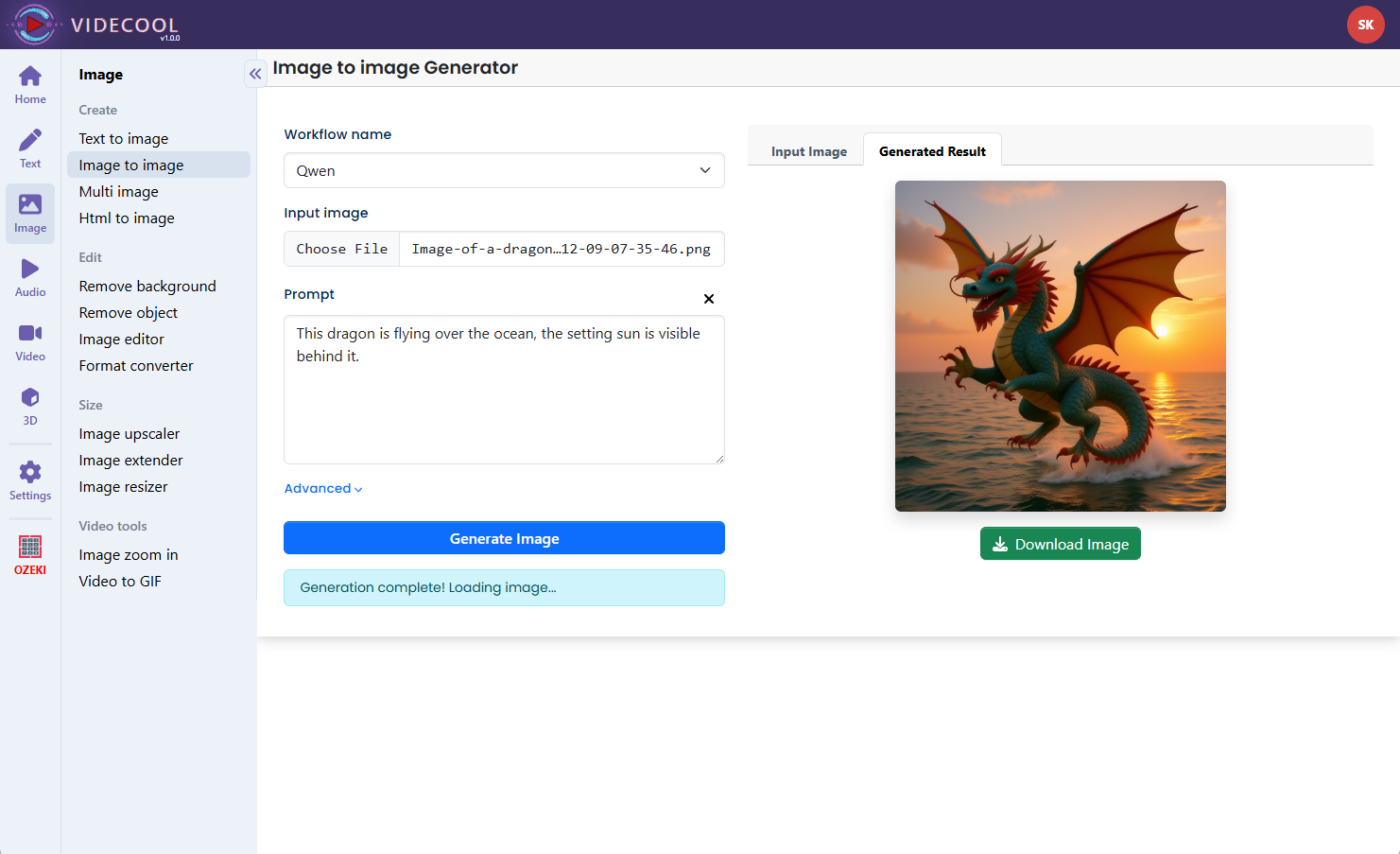
Example usage in Videcool
Download the ComfyUI workflow
Download ComfyUI Workflow file: qwen_image2image-api.json
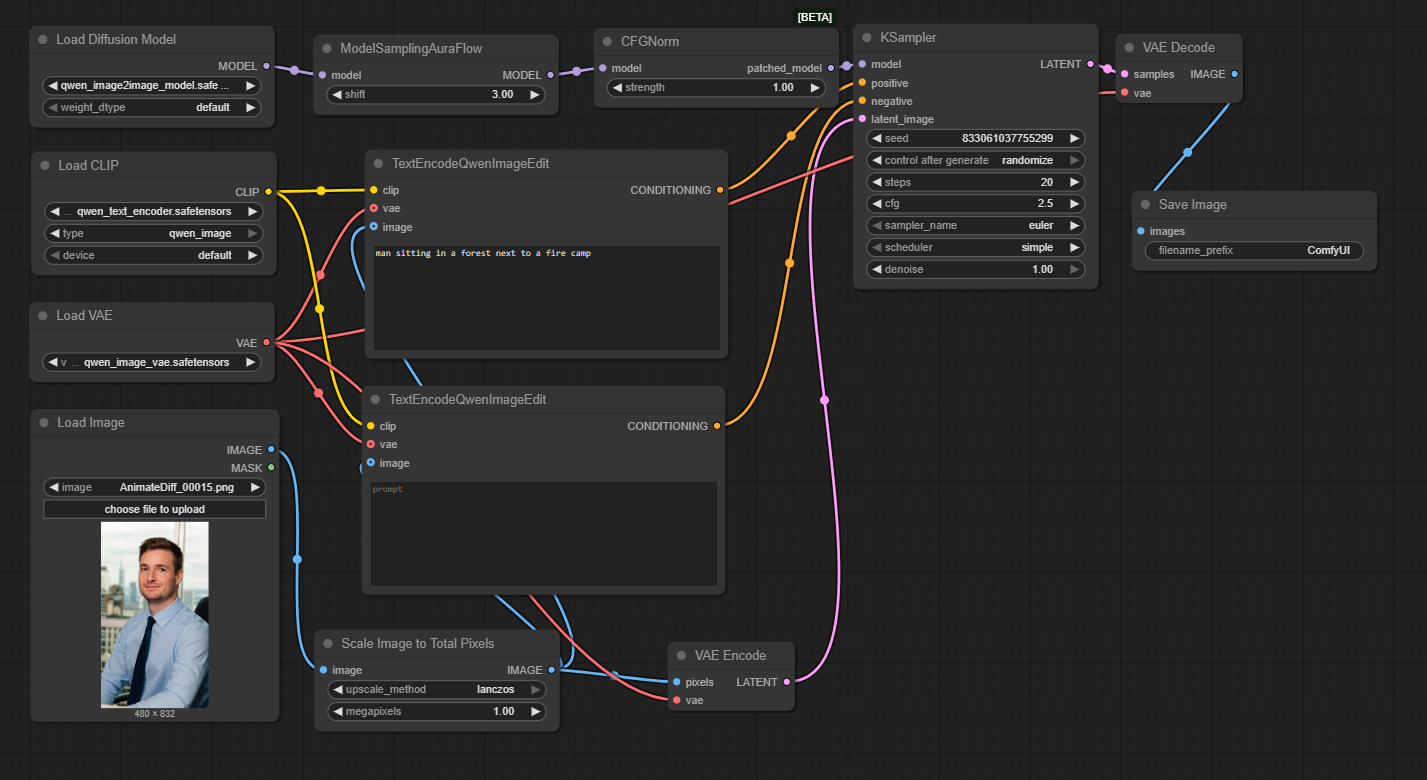
Image of the ComfyUI workflow
This figure provides a visual overview of the Qwen Image-to-Image workflow layout inside ComfyUI. Each node is placed in logical order to establish a clean and efficient image transformation pipeline, starting from loading the source image and model, through text encoding, conditioning, sampling, and final decoding. The structure makes it easy to understand how the Qwen model, text encoder, VAE, and sampler interact. Users can modify or expand parts of the workflow to create custom variations or integrate image transformation into larger creative pipelines.
Installation steps
Step 1: Download qwen_image_edit_fp8_e4m3fn.safetensors into /ComfyUI/models/diffusion_models/ and rename it to qwen_image2image_model.safetensors.Step 2: Download qwen_image_vae.safetensors into /ComfyUI/models/vae/qwen_image_vae.safetensors.
Step 3: Download qwen_2.5_vl_7b_fp8_scaled.safetensors into /ComfyUI/models/text_encoders/qwen_text_encoder.safetensors.
Step 4: Download the qwen_image2image-api.json workflow file into your home directory.
Step 5: Restart ComfyUI so the new model and encoder files are recognized.
Step 6: Open the ComfyUI graphical user interface (ComfyUI GUI).
Step 7: Load the qwen_image2image-api.json workflow in the ComfyUI GUI.
Step 8: In the Load Image node, select the source image you want to transform.
Step 9: Enter a text prompt describing the desired transformation or editing in the text encoding node, then hit run to generate the transformed image.
Step 10: Open Videcool in your browser, select the Image to Image Qwen tool, and use the generated outputs for further compositing, video creation, or design work.
Installation video
The workflow requires a source image, an optional text prompt, and a few basic parameter adjustments to begin transforming images. After loading the JSON file, users can select the input image, enter edit instructions, adjust sampling quality and steps, and then run the pipeline to obtain a transformed version. Once executed, the sampler produces a new image that maintains key structural elements while applying the requested changes, which can be saved and reused across other Videcool tools.
Prerequisites
To run the workflow correctly, download the Qwen model files and text encoder, then place them into your ComfyUI directory. These files ensure the model can understand the input image, interpret text instructions, and produce high-quality transformed outputs. Proper installation into the following location is essential before running the workflow: {your ComfyUI director}/models.
ComfyUI\models\diffusion_models\qwen_image2image_model.safetensors
https://huggingface.co/Comfy-Org/Qwen-Image-Edit_ComfyUI/resolve/main/split_files/diffusion_models/qwen_image_edit_fp8_e4m3fn.safetensors
ComfyUI\models\vae\qwen_image_vae.safetensors
https://huggingface.co/Comfy-Org/Qwen-Image_ComfyUI/resolve/main/split_files/vae/qwen_image_vae.safetensors
ComfyUI\models\text_encoders\qwen_text_encoder.safetensors
https://huggingface.co/Comfy-Org/Qwen-Image_ComfyUI/resolve/main/split_files/text_encoders/qwen_2.5_vl_7b_fp8_scaled.safetensors
How to use this workflow in Videcool
Videcool integrates seamlessly with ComfyUI, allowing users to load and run Qwen image transformation workflows directly without managing the underlying node graph. After importing the workflow file into ComfyUI, Videcool can call it to transform images based on text prompts and user preferences. This makes image editing and transformation intuitive and accessible, even for users who are not keen on learning how ComfyUI works, while still benefiting from the power of the Qwen Image-to-Image model.
ComfyUI nodes used
This workflow uses the following nodes. Each node performs a specific role, such as loading the source image and model, encoding text instructions, preparing the image for processing, sampling, and finally decoding and saving the output. Together they create a reliable and modular pipeline that can be easily extended or customized for different image transformation tasks.
- KSampler
- VAE Decode
- Load Diffusion Model
- Load VAE
- Save Image
- Load Image
- VAE Encode
- Load CLIP
- ModelSamplingAuraFlow
- CFGNorm
- TextEncodeQwenImageEdit
- Scale Image to Total Pixels
Base AI model
This workflow is built on the Qwen Image-to-Image model, a powerful vision model developed by Alibaba's Qwen team and repackaged for ComfyUI by Comfy-Org. The Qwen model excels at understanding both visual and textual inputs, allowing it to perform flexible image transformations guided by prompts. The model provides strong performance across diverse image editing scenarios, including style changes, content modifications, and context-aware image generation based on source material.
Hugging Face Qwen Image-to-Image (Edit) repository:https://huggingface.co/Comfy-Org/Qwen-Image-Edit_ComfyUI
Hugging Face Qwen Image ComfyUI repository:https://huggingface.co/Comfy-Org/Qwen-Image_ComfyUI
Image resolution
Qwen Image-to-Image workflows perform well with a wide range of image resolutions. For best results, use input images with dimensions that are multiples of 32 pixels, which keeps the internal latent representation aligned with the model's architecture. Standard resolutions like 512×512, 768×768, or 1024×1024 provide a good balance between detail preservation and processing time. Larger resolutions are supported but may require more VRAM, so adjust based on your hardware capabilities.
Conclusion
The Qwen Image to Image ComfyUI workflow is a robust, powerful, and user-friendly solution for performing flexible image transformations in Videcool. With its combination of the advanced Qwen model, a modular ComfyUI pipeline, and seamless platform integration, it enables beginners and professionals alike to produce creative image edits and variations with ease. By understanding the workflow components and installation steps, users can unlock the full potential of AI-assisted image-to-image transformation in Videcool.